메타 Autodata 해설: 합성 데이터 경쟁이 프롬프트 한 번 생성에서 반복 검증 루프로 넘어가는 이유
AI타임스가 전한 메타의 Autodata 공개를 바탕으로, 합성 데이터 생성이 왜 단발성 프롬프트보다 반복 검증 루프와 약·강 모델 분리 평가로 이동하는지 실무 기준으로 정리했습니다.
메타 Autodata 해설: 합성 데이터 경쟁이 프롬프트 한 번 생성에서 반복 검증 루프로 넘어가는 이유
발행일: 2026-05-05 | 카테고리: 개발정보
1) 한 줄 문제 정의
핵심 요약: 모델을 더 크게 만드는 것만으로는 성능이 계속 오르지 않는 시점에서, 병목은 점점 학습 데이터의 품질 관리 방식으로 이동하고 있습니다.
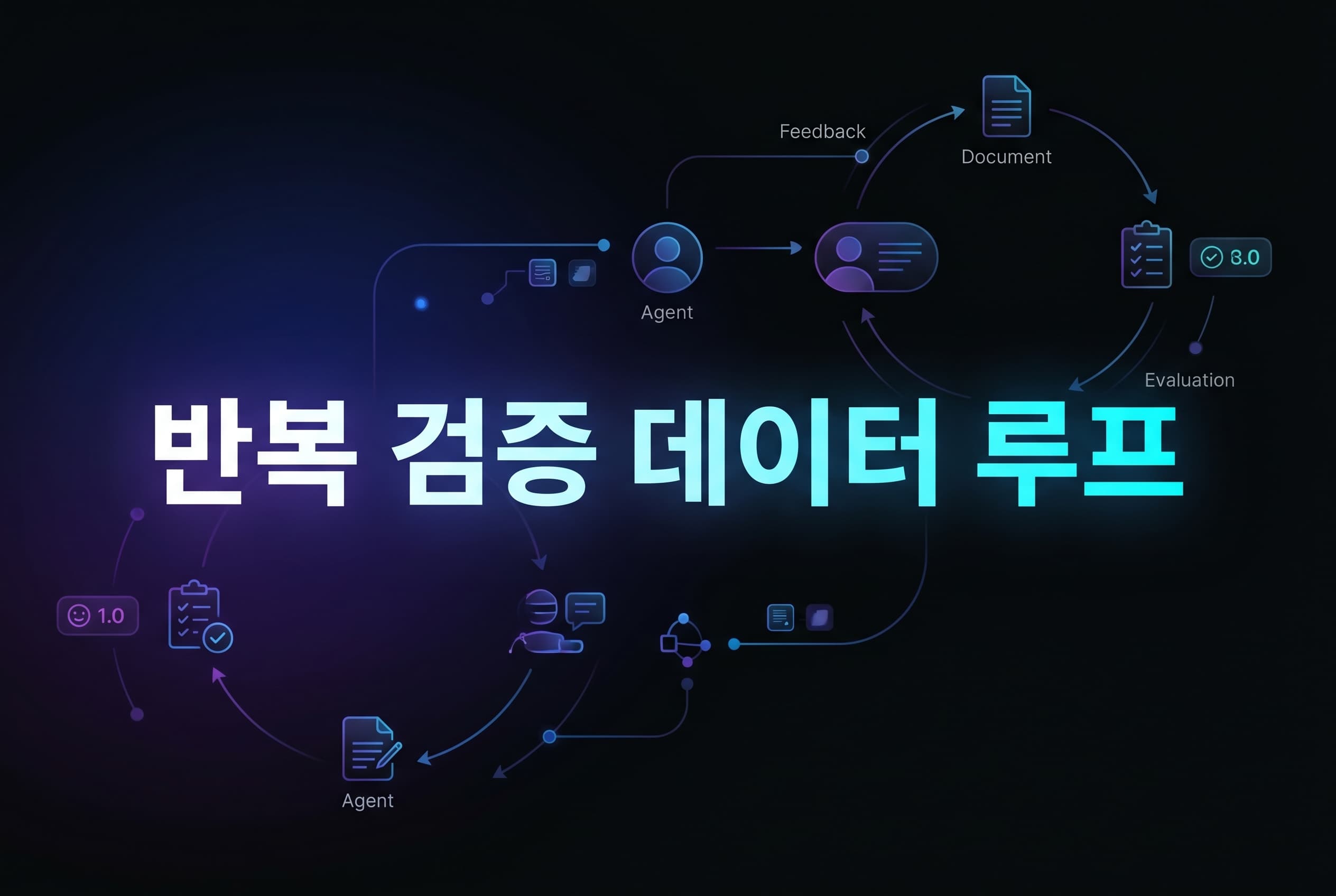
AI타임스는 2026년 5월 5일 메타가 Autodata라는 새 프레임워크를 공개했다고 전했습니다. 겉으로 보면 또 하나의 합성 데이터 자동화 소식처럼 보일 수 있습니다. 하지만 실무적으로 더 중요한 변화는 따로 있습니다. 이제 데이터 생성은 “프롬프트 한 번 던져 예제를 많이 뽑는 일”이 아니라, 약한 모델은 틀리고 강한 모델은 맞히는 문제를 반복적으로 발굴하고 검증하는 운영 루프로 바뀌고 있다는 점입니다.
이 글은 LLM 학습팀, 평가셋 운영팀, AI 제품팀, 데이터 엔지니어, 에이전트 워크플로 설계자를 위한 해설입니다. 범위는 Autodata의 구조, 기존 Self-Instruct류 방식과 차이, 실무 도입 판단 기준입니다. 반대로 메타가 곧바로 모든 학습 데이터를 완전 자동으로 대체했다는 식의 과장은 다루지 않습니다.
2) 먼저 결론
핵심 요약: 이번 발표의 본질은 데이터 양 확대가 아니라, 추론 시간과 에이전트 루프를 더 써서 데이터의 난이도와 분별력을 올리겠다는 선언입니다.
- 지금 바로 참고할 팀: 평가셋이 너무 쉬워 모델 차이가 잘 안 보이거나, 합성 데이터는 많은데 실제 학습 이득이 약한 팀
- 아직 과한 팀: 아직 기본 데이터 정제와 라벨 품질 관리도 안 된 초기 팀, 또는 소형 태스크 한두 개만 다루는 팀
- 제 판단: Autodata의 핵심 가치는 “더 많이 생성”이 아니라 어떤 예제가 학습 가치가 있는지를 에이전트가 스스로 찾아내고 개선한다는 데 있습니다.
쉽게 말해, 기존 방식이 대량 복사와 선별에 가까웠다면 Autodata는 문제를 만들고, 시험해 보고, 왜 별로였는지 분석하고, 다시 출제하는 데이터 과학자 루프에 가깝습니다. 그래서 앞으로 합성 데이터 경쟁력은 프롬프트 문장 몇 줄보다, 검증 기준·약강 모델 분리·반복 개선 구조를 얼마나 잘 설계했는지에서 갈릴 가능성이 큽니다.
3) 핵심 구조 분해
핵심 요약: Autodata는 단일 생성기가 아니라 생성-분석-개선-메타최적화의 4층 구조로 이해해야 합니다.
- 데이터 생성 계층: 메인 에이전트가 논문, 코드, 문서 같은 근거 자료를 바탕으로 학습용 또는 평가용 예제를 만듭니다.
- 데이터 분석 계층: 방금 만든 예제가 정확한지, 충분히 어렵고 다양한지, 실제로 모델 성능 차이를 드러내는지 검사합니다.
- 반복 개선 계층: 분석 결과를 받아 생성 프롬프트와 출제 방향을 바꾸고 다시 예제를 만듭니다. 메타 공개 자료 기준으로 CS 연구 태스크에서는 한 논문당 보통 3~5회 반복한 뒤 채택 여부를 결정했습니다.
- 메타최적화 계층: 데이터 만드는 에이전트 자체의 하네스와 루프도 다시 최적화합니다. 즉 사람이 프롬프트를 수동 튜닝하는 대신, 에이전트의 출제 습관 자체를 개선하는 바깥 루프가 추가됩니다.
이 구조를 초보 개발자 기준으로 비유하면 이렇습니다. 기존 합성 데이터 방식은 문제집 자동 생성기였다면, Autodata는 출제자 + 채점자 + 모의고사 분석관 + 문제집 편집장을 한 팀으로 묶은 셈입니다. 그래서 예제 수보다 예제의 분별력, 즉 약한 모델과 강한 모델을 얼마나 잘 갈라내는가가 더 중요한 지표가 됩니다.
4) 설계 의도 해설
핵심 요약: 메타는 합성 데이터의 가장 큰 한계를 “자동 생성”이 아니라 자동 생성 뒤 품질을 제어하지 못하는 것으로 보고 있습니다.
Self-Instruct 계열은 분명 중요한 진전이었습니다. 하지만 실무에서 자주 부딪히는 문제는 따로 있습니다. 예제는 수만 개가 쌓였는데, 막상 모델을 학습시키면 기존보다 별 차이가 없거나, 오히려 쉬운 문제만 늘어나는 경우가 많습니다. Autodata는 이 지점을 정면으로 겨냥합니다.
메타의 공개 설명에 따르면 Agentic Self-Instruct는 Challenger, Weak Solver, Strong Solver, Verifier/Judge 네 하위 에이전트를 둡니다. 핵심은 “좋은 문제”의 기준을 단순 정답 여부가 아니라, 약한 모델은 실패하고 강한 모델은 통과하는지로 재정의한 점입니다. 이 기준이 있어야 학습 데이터가 정말로 더 상위 능력을 밀어주는 방향으로 정렬됩니다.
- 얻는 것: 더 어려우면서도 채점 가능한 데이터, 모델 간 분별력 향상, 추론 시간을 데이터 품질로 전환하는 경로
- 포기하는 것: 생성 속도, 단순성, 비용 예측의 쉬움
- 실무 해석: 이제 합성 데이터 파이프라인은 “얼마나 빨리 뽑나”보다 “얼마나 유효한 실패와 유효한 성공을 설계하나”가 더 중요해집니다.
제가 보기에는 이 발표가 중요한 이유가 바로 여기에 있습니다. 메타는 추론 시 계산량을 늘려 더 나은 정답을 만드는 데서 한 걸음 더 나아가, 그 계산량으로 더 나은 학습 데이터 자체를 만든다는 방향을 제시했습니다. 이는 inference compute를 training data quality로 바꾸는 접근입니다.
5) 근거 및 비교
핵심 요약: Autodata를 볼 때는 일반적인 합성 데이터 생성기와 비교해야지, 단순히 “에이전트가 있다”는 문장만 보면 핵심이 빠집니다.
| 비교 기준 | 수동 작성/라벨링 | 단발성 Self-Instruct | Autodata / Agentic Self-Instruct |
|---|---|---|---|
| 기본 방식 | 사람이 직접 문제와 답을 작성 | 모델이 한 번에 예제 생성 | 에이전트가 생성→평가→개선 반복 |
| 강점 | 도메인 통제력 높음 | 빠르고 싸게 대량 생성 가능 | 분별력 높은 어려운 데이터 축적 가능 |
| 약점 | 속도와 비용 부담 큼 | 쉬운 예제 과다, 품질 편차 큼 | 연산량·운영 복잡도 증가 |
| 품질 판단 기준 | 사람 검토 중심 | 필터링 중심 | 약·강 모델 간 점수 차이 + 판정 루브릭 |
| 추천 상황 | 법률·의료처럼 고정밀 소량 데이터 | 초기 부트스트랩 | 추론·연구형 태스크의 고품질 학습/평가셋 |
공개된 수치도 방향을 분명하게 보여줍니다.
- 메타 RAM 공식 페이지: 2022년 이후 1만 개 이상의 CS 논문을 처리해, 품질 기준을 통과한 2117개 QA 쌍을 생성했다고 설명합니다.
- 같은 공식 페이지: CoT Self-Instruct에서는 약한 모델 71.4%, 강한 모델 73.3%로 차이가 거의 없었지만, Agentic Self-Instruct에서는 약한 모델 43.7%, 강한 모델 77.8%로 격차를 크게 벌렸다고 제시합니다.
- 메타최적화 결과: 검증 기준 통과율이 12.8% → 42.4%로 상승했고, 총 233회 반복 중 126회가 채택됐다고 공개했습니다.
이 숫자가 시사하는 바는 단순합니다. 좋은 데이터란 “정답이 있는 데이터”가 아니라, 약한 모델은 잘 틀리고 강한 모델만 제대로 풀 수 있는 데이터일 수 있다는 점입니다. 특히 연구형 QA, 코드 reasoning, 장문 문서 이해처럼 쉬운 벤치마크가 금방 포화되는 영역에서는 이 차이가 매우 큽니다.
6) 실제 동작 흐름 / 단계별 실행 방법
핵심 요약: 지금 팀이 바로 따라 할 수 있는 핵심은 메타와 똑같은 스택을 복제하는 일이 아니라, 약·강 모델 분리 평가 루프를 먼저 도입하는 것입니다.
- 기반 문서를 좁혀 잡으십시오.
처음부터 전 분야 문서에 적용하지 말고, 논문 100편이나 내부 기술 문서 200개처럼 범위를 제한합니다. - 약한 모델과 강한 모델을 명시적으로 나누십시오.
예: 4B급 또는 경량 사내 모델을 weak, 상위 API 모델 또는 더 긴 추론 허용 버전을 strong으로 둡니다. - 출제 기준을 정답률이 아니라 격차로 정의하십시오.
예를 들어 weak 평균 점수 65% 이하, strong과의 격차 20% 이상 같은 규칙을 둡니다. - 루브릭 기반 판정을 추가하십시오.
정답 문자열만 비교하지 말고, 왜 맞고 왜 틀렸는지 판정 기준을 항목화합니다. - 실패 원인을 생성기로 되돌리십시오.
너무 쉬웠는지, strong도 같이 틀렸는지, 문맥 누출이 있었는지 구분해 다음 프롬프트에 반영합니다. - 종료 조건을 두십시오.
반복 횟수 상한, 예제당 최대 비용, accepted 비율 하한을 두지 않으면 파이프라인이 끝없이 길어질 수 있습니다.
# 최소 운영 초안
accept_if = (weak_avg <= 65) and ((strong_avg - weak_avg) >= 20) and quality_verifier_pass
for doc in source_docs:
for round in range(1, 6):
example = challenger.generate(doc, feedback)
qv = verifier.check(example)
if not qv.pass:
feedback = qv.feedback
continue
weak_avg = eval_model(weak_model, example)
strong_avg = eval_model(strong_model, example)
if accept_if:
save(example)
break
feedback = analyze_failure(example, weak_avg, strong_avg)많은 팀이 여기서 실수합니다. 합성 데이터 문제를 “프롬프트를 더 길게 쓰면 해결된다”로 봅니다. 하지만 실제로는 어떤 예제를 버리고 어떤 예제를 살릴지 결정하는 판정 구조가 훨씬 더 중요합니다.
7) 실수/함정(Pitfalls)
핵심 요약: Autodata류 접근은 강력하지만, 잘못 쓰면 그럴듯한 자동화만 늘고 실제 학습 가치는 오히려 떨어질 수 있습니다.
- 실수 1: 강한 모델도 자주 틀리는 문제를 좋은 데이터로 착각
예방: weak 실패뿐 아니라 strong 최소 점수 기준을 따로 둡니다. 복구: accepted 데이터셋에서 strong 저득점 샘플을 분리 제거합니다. - 실수 2: 루브릭 없이 점수만 비교
예방: 판정자에게 세부 채점 항목을 명시합니다. 복구: 기존 예제를 다시 채점해 왜 weak와 strong이 갈렸는지 설명 가능한 구조로 바꿉니다. - 실수 3: 문맥 누출과 정답 유출을 방치
예방: quality verifier 단계에서 context leakage를 검사합니다. 복구: 출제 컨텍스트와 답안 힌트가 겹치는 샘플을 대량 재검토합니다. - 실수 4: 연산비 상한 없이 무한 반복
예방: 문서당 최대 라운드 수와 accepted 비율 기준을 정합니다. 복구: 반복 로그를 보고 특정 실패 패턴이 많은 출제 템플릿을 제거합니다. - 실수 5: 합성 데이터만 늘고 실제 학습 검증을 안 함
예방: holdout 셋과 소형 RL/SFT 실험으로 실제 향상을 확인합니다. 복구: 데이터 생성량 KPI를 줄이고, 학습 후 성능 차이를 기본 KPI로 승격합니다.
8) 강점과 한계
핵심 요약: Autodata는 합성 데이터의 운영 수준을 한 단계 올렸지만, 모든 도메인에 바로 만능 해법이 되지는 않습니다.
강점
- 단발성 생성보다 훨씬 분별력 높은 예제를 만들 수 있습니다.
- 추론 시간을 더 써서 학습 데이터 품질로 바꾸는 경로를 제공합니다.
- 평가셋과 학습셋을 같은 품질 루프로 관리할 수 있습니다.
- 데이터 과학자의 분석 업무 일부를 에이전트 루프로 구조화합니다.
한계
- 연산량과 운영 복잡도가 크게 늘어납니다.
- 판정자와 strong solver가 흔들리면 전체 품질 기준도 함께 흔들립니다.
- 의료, 법률, 규제 문서처럼 정답 검증 비용이 높은 분야에서는 사람 검수가 여전히 강하게 필요합니다.
- 메타도 공개 자료에서 규칙 회피나 편법 행동 가능성을 한계로 언급했습니다.
반례: 범용 챗봇 튜닝처럼 이미 대규모 사람 피드백과 운영 로그가 풍부한 영역에서는 Autodata보다 데이터 정제, 안전성 필터, 배포 후 피드백 루프가 더 큰 효과를 낼 수도 있습니다.
9) 더 깊게 공부할 포인트
핵심 요약: 이 발표를 제대로 활용하려면 ‘합성 데이터’보다 데이터 분별력이라는 단어를 먼저 이해해야 합니다.
- 우리 팀의 현재 평가셋은 약한 모델과 강한 모델을 실제로 구분해 주는가
- 문제 생성기보다 quality verifier와 rubric 설계가 더 병목은 아닌가
- Self-Instruct, grounded generation, challenging generation을 어떤 순서로 섞어야 하는가
- 합성 데이터 품질을 실제 학습 이득과 연결해 측정할 수 있는가
- 데이터 생성 에이전트의 실패 로그를 메타최적화 입력으로 다시 쓸 수 있는가
초보 개발자라면 먼저 Self-Instruct가 무엇이었고, 왜 한 번 생성 방식만으로는 모델 차이를 잘 드러내지 못하는지부터 이해하는 편이 좋습니다. 그 다음에야 Autodata의 반복 루프가 왜 의미 있는지 자연스럽게 보입니다.
10) 실행 체크리스트 + 작성자 관점
핵심 요약: Autodata의 실무 가치는 화려한 멀티에이전트 구성보다, 좋은 데이터의 기준을 다시 정의했다는 데 있습니다.
- 현재 합성 데이터 파이프라인에 weak vs strong 분리 평가가 있는가?
- accepted 샘플의 기준이 단순 정답 여부가 아니라 분별력으로 정의돼 있는가?
- quality verifier가 문맥 누출, 루브릭 누락, 너무 쉬운 문제를 걸러내는가?
- 문서당 최대 반복 횟수와 비용 상한이 정해져 있는가?
- 생성된 데이터가 실제 학습 실험에서 이득을 내는지 holdout으로 검증하는가?
- 데이터 생성기의 실패 로그를 다음 라운드 개선에 쓰는 구조가 있는가?
- 강한 모델조차 자주 틀리는 샘플과 weak만 틀리는 샘플을 분리 보고 있는가?
Definition of Done: 우리 팀이 최소 한 도메인에서 weak/strong 분리 기준, 루브릭 기반 판정, 반복 개선 로그, 학습 후 성능 검증까지 연결된 합성 데이터 루프를 문서화하고 재현할 수 있으면 1차 도입이 완료된 것입니다.
제 추천: 이번 메타 발표는 “에이전트가 데이터도 만든다” 정도로 읽으면 아깝습니다. 핵심은 합성 데이터 운영을 생성 중심에서 검증 중심으로 뒤집었다는 점입니다. 저는 연구형 QA, 코드 reasoning, 장문 문서 이해처럼 쉬운 벤치마크가 빨리 포화되는 팀이라면 지금 바로 작은 파일럿을 권합니다. 반대로 아직 데이터 정제, 기준선 모델, 품질 검수 체계도 약한 팀은 Autodata 전체를 흉내 내기보다 먼저 기존 데이터 품질 관리부터 고정하는 편이 낫습니다.
참고자료
- AI타임스 - 메타, '더 오래 생각'하며 고품질 데이터 생성하는 ‘오토데이터’ 공개 (발행일: 2026-05-05, 확인일: 2026-05-05)
- Meta RAM - Autodata: an automatic data scientist to create high-quality data (게시일: 2026-05-01, 확인일: 2026-05-05)
- Self-Instruct: Aligning Language Models with Self-Generated Instructions (게시일: 2022-12-20, 확인일: 2026-05-05)
- AllenAI - S2ORC Corpus (확인일: 2026-05-05)
공유하기
관련 글

TypeScript 7.0 RC 해설: Go 네이티브 컴파일러 전환은 속도보다 마이그레이션 경계와 도구 호환성을 먼저 봐야 하는 이유
TypeScript 7.0 RC는 Go 기반 네이티브 컴파일러로 전환되는 큰 변화입니다. 10배 빠른 빌드보다 중요한 것은 tsc 6.0과의 병행, 프로그램 API 공백, CI 검증 경계를 먼저 설계하는 일입니다.

OpenAI 자율 AI 화학자 해설: AI 연구 자동화는 모델 성능보다 실험실 연결·사람 검증·재현 루프를 먼저 설계해야 하는 이유
AI타임스가 전한 OpenAI·Molecule.one의 자율 AI 화학자 프로젝트를 개발자와 AI 도입 담당자 관점에서 해설합니다. GPT-5.4가 Maria Lab과 연결돼 1만80건의 실험을 수행한 사례를 통해, 연구 자동화 시스템에서 모델·실험실·사람 검증 경계를 어떻게 나눠야 하는지 정리했습니다.

Cloudflare Agents SDK v0.16.1 해설: 브라우저·코드 실행 에이전트는 기능보다 실행 경계와 복구 로그를 먼저 설계해야 하는 이유
Cloudflare Agents SDK v0.16.1의 Browser Run, Codemode, sub-agent delegation, 복구 개선을 개발자 관점에서 해설합니다. 브라우저 자동화와 코드 실행을 열기 전에 권한, 승인, 세션, 재개 로그를 어떻게 나눌지 실무 체크리스트로 정리했습니다.
AQ 테스트 해보기
지금 내 AI 활용 능력이 어느 수준인지 3분 안에 확인해보세요. 인지력, 활용력, 검증력, 통합력, 윤리감을 한 번에 진단하고 맞춤형 인사이트를 받아볼 수 있습니다.
무료 AQ 테스트 시작하기